目錄
@
前言
你是否真的理解java的類加載機制?點進文章的盆友不如先來做一道非常常見的面試題,如果你能做出來,可能你早已掌握並理解了java的類加載機制,若結果出乎你的意料,那就很有必要來了解了解java的類加載機制了。代碼如下
package com.jvm.classloader;
class Father2{
public static String strFather="HelloJVM_Father";
static{
System.out.println("Father靜態代碼塊");
}
}
class Son2 extends Father2{
public static String strSon="HelloJVM_Son";
static{
System.out.println("Son靜態代碼塊");
}
}
public class InitativeUseTest2 {
public static void main(String[] args) {
System.out.println(Son2.strSon);
}
}
運行結果:
Father靜態代碼塊
Son靜態代碼塊
HelloJVM_Son
嗯哼?其實上面程序並不是關鍵,可能真的難不倒各位,不妨做下面一道面試題可好?如果下面這道面試題都做對了,那沒錯了,這篇文章你就不用看了,真的。
package com.jvm.classloader;
class YeYe{
static {
System.out.println("YeYe靜態代碼塊");
}
}
class Father extends YeYe{
public static String strFather="HelloJVM_Father";
static{
System.out.println("Father靜態代碼塊");
}
}
class Son extends Father{
public static String strSon="HelloJVM_Son";
static{
System.out.println("Son靜態代碼塊");
}
}
public class InitiativeUse {
public static void main(String[] args) {
System.out.println(Son.strFather);
}
}
各位先用“畢生所學”來猜想一下運行的結果是啥…
注意了…
注意了…
注意了…
運行結果:
YeYe靜態代碼塊
Father靜態代碼塊
HelloJVM_Father
是對是錯已經有個數了吧,我就不拆穿各位的小心思了…
以上的面試題其實就是典型的java類的加載問題,如果你對Java加載機制不理解,那麼你可能就錯了上面兩道題目的。這篇文章將通過對Java類加載機制的講解,讓各位熟練理解java類的加載機制。
其實博主還是想在給出一道題,畢竟各位都已經有了前面兩道題的基礎了,那麼請看代碼:
package com.jvm.classloader;
class YeYe{
static {
System.out.println("YeYe靜態代碼塊");
}
}
class Father extends YeYe{
public final static String strFather="HelloJVM_Father";
static{
System.out.println("Father靜態代碼塊");
}
}
class Son extends Father{
public static String strSon="HelloJVM_Son";
static{
System.out.println("Son靜態代碼塊");
}
}
public class InitiativeUse {
public static void main(String[] args) {
System.out.println(Son.strFather);
}
}
注意了
注意了
注意了
運行結果:HelloJVM_Father
衝動的小白童鞋看到了運行結果,果斷的註銷了博客賬戶….
1、什麼是類的加載(類初始化)
JVM重要的一個領域:類加載
當程序主動使用某個類時,如果該類還未被加載到內存中,則JVM會通過加載、連接、初始化3個步驟來對該類進行初始化。如果沒有意外,JVM將會連續完成3個步驟,所以有時也把這個3個步驟統稱為類加載或類初始化。
而類加載必然涉及類加載器,下面我們先來了解一下類的加載。
類的加載(類初始化):
1、在java代碼中,類型的加載、連接、與初始化過程都是在程序運行期間完成的(類從磁盤加載到內存中經歷的三個階段)【牢牢記在心裏】
2、提供了更大的靈活性,增加了更多的可能性
雖然上面的第一句話非常簡短,但是蘊含的知識量卻是巨大的!包含兩個重要的概念:
1、類型
定義的類、接口或者枚舉稱為類型而不涉及對象,在類加載的過程中,是一個創建對象之前的一些信息
2、程序運行期間
程序運行期間完成典型例子就是動態代理,其實很多語言都是在編譯期就完成了加載,也正因為這個特性給Java程序提供了更大的靈活性,增加了更多的可能性
1、1.類加載注意事項
1、類加載器並不需要等到某個類被 “首次主動使用” 時再加載它~關於首次主動使用這個重要概念下文將講解~
2、JVM規範允許類加載器在預料某個類將要被使用時就預先加載它
3、如果在預先加載的過程中遇到了.class文件缺失或存在錯誤,類加載器必須在程序首次主動使用該類時才報告錯誤(LinkageError錯誤)如果這個類一直沒有被程序主動使用,那麼類加載器就不會報告錯誤。
首先給各位打個預防針:可能沒有了解過JVM的童鞋可能看的很蒙,感覺全是理論的感覺,不勉強一字一句的“死看”,只要達到一種概念印象就好!等到有一定理解認識之後再回頭看一遍就好很多了,畢竟學習是一種循進漸進的過程,記住沒有捷徑!
2、類的生命周期
從上圖可知,類從被加載到虛擬機內存開始,到卸載出內存為止,它的整個生命周期包括 7 個階段,而驗證、準備、解析 3 個階段統稱為連接。
加載、驗證、準備、初始化和卸載這 5 個階段的順序是固定確定的,類的加載過程必須按照這種順序開始(注意是“開始”,而不是“進行”),而解析階段則不一定:它在某些情況下可以在初始化后再開始,這是為了支持 Java 語言的運行時綁定【也就是java的動態綁定/晚期綁定】。
2、1.加載
在上面已經提到過,加載階段是類加載的第一個階段!類的加載過程就是從加載階段開始~
加載階段指的是將類的.class文件中的二進制數據讀入到內存中,將其放在運行時數據區的方法區內,然後在堆區創建一個 java.lang.Class對象(JVM規範並未說明Class對象位於哪裡,HotSpot虛擬機將其放在方法區中),用來封裝類在方法區內的數據結構。類的加載的最終產品是位於堆區中的 Class對象, Class對象封裝了類在方法區內的數據結構,並且向Java程序員提供了訪問方法區內的數據結構的接口。
Class對象是存放在堆區的,不是方法區,這點很多人容易犯錯。類的元數據才是存在方法區的。【元數據並不是類的Class對象。Class對象是加載的最終產品,類的方法代碼,變量名,方法名,訪問權限,返回值等等都是在方法區的】
JDK7創建Class實例存在堆中;因為JDK7中JavaObjectsInPerm參數值固定為false。
JDK8移除了永久代,轉而使用元空間來實現方法區,創建的Class實例依舊在java heap(堆)中
編寫一個新的java類時,JVM就會幫我們編譯成class對象,存放在同名的.class文件中。在運行時,當需要生成這個類的對象,JVM就會檢查此類是否已經裝載內存中。若是沒有裝載,則把.class文件裝入到內存中。若是裝載,則根據class文件生成實例對象。
怎麼理解Class對象與new出來的對象之間的關係呢?
new出來的對象以car為例。可以把car的Class類看成具體的一個人,而new car則是人物映像,具體的一個人(Class)是唯一的,人物映像(new car)是多個的。鏡子中的每個人物映像都是根據具體的人映造出來的,也就是說每個new出來的對象都是以Class類為模板參照出來的!為啥可以參照捏?因為Class對象提供了訪問方法區內的數據結構的接口哇,上面提及過了喔!
算了參照下面這張圖理解吧,理解是其次,重點是話說這妹砸蠻好看的。
總結:
加載階段簡單來說就是:
.class文件(二進制數據)——>讀取到內存——>數據放進方法區——>堆中創建對應Class對象——>並提供訪問方法區的接口
相對於類加載的其他階段而言,加載階段(準確地說,是加載階段獲取類的二進制字節流的動作)是可控性最強的階段,因為開發人員既可以使用系統提供的類加載器來完成加載,也可以自定義自己的類加載器來完成加載。
加載階段完成后,虛擬機外部的二進制字節流就按照虛擬機所需的格式存儲在方法區之中,而且在Java堆中也創建一個 java.lang.Class類的對象,這樣便可以通過該對象訪問方法區中的這些數據。
加載.calss文件的方式:
類的加載由類加載器完成,類加載器通常由JVM提供,這些類加載器也是前面所有程序運行的基礎,JVM提供的這些類加載器通常被稱為系統類加載器。除此之外,開發者可以通過繼承ClassLoader基類來創建自己的類加載器。通過使用不同的類加載器,可以從不同來源加載類的二進制數據,二進制數據通常有如下幾種來源:
(1)從本地系統中直接加載
(2)通過網絡下載.class文件
(3)從zip,jar等歸檔文件中加載.class文件
(4)從專用數據庫中提取.class文件
(5)將java源文件動態編譯為.class文件
2、2.驗證
驗證:確保被加載的類的正確性。
關於驗證大可不必深入但是了解類加載機制必須要知道有這麼個過程以及知道驗證就是為了驗證確保Class文件的字節流中包含的信息符合當前虛擬機的要求即可。
所以下面關於驗證的內容作為了解即可!
驗證是連接階段的第一階段,這一階段的目的是為了確保Class文件的字節流中包含的信息符合當前虛擬機的要求,並且不會危害虛擬機自身的安全。驗證階段大致會完成4個階段的檢驗動作:
文件格式驗證:驗證字節流是否符合Class文件格式的規範;例如:是否以 0xCAFEBABE開頭、主次版本號是否在當前虛擬機的處理範圍之內、常量池中的常量是否有不被支持的類型。
元數據驗證:對字節碼描述的信息進行語義分析(注意:對比javac編譯階段的語義分析),以保證其描述的信息符合Java語言規範的要求;例如:這個類是否有父類,除了 java.lang.Object之外。
字節碼驗證:通過數據流和控制流分析,確定程序語義是合法的、符合邏輯的。
符號引用驗證:確保解析動作能正確執行。
驗證階段是非常重要的,但不是必須的,它對程序運行期沒有影響,如果所引用的類經過反覆驗證,那麼可以考慮採用 -Xverifynone參數來關閉大部分的類驗證措施,以縮短虛擬機類加載的時間。
2、3.準備【重點】
當完成字節碼文件的校驗之後,JVM 便會開始為類變量分配內存並初始化。準備階段是正式為類變量分配內存並設置類變量初始值的階段,這些內存都將在方法區中分配。
這裏需要注意兩個關鍵點,即內存分配的對象以及初始化的類型。
內存分配的對象:要明白首先要知道Java 中的變量有類變量以及類成員變量兩種類型,==類變量指的是被 static 修飾的變量==,而==其他所有類型的變量都屬於類成員變量==。在準備階段,JVM 只會為類變量分配內存,而不會為類成員變量分配內存。類成員變量的內存分配需要等到初始化階段才開始(初始化階段下面會講到)。
舉個例子:例如下面的代碼在準備階段,只會為 LeiBianLiang屬性分配內存,而不會為 ChenYuanBL屬性分配內存。
public static int LeiBianLiang = 666;
public String ChenYuanBL = "jvm";
初始化的類型:在準備階段,JVM 會為類變量分配內存,併為其初始化(JVM 只會為類變量分配內存,而不會為類成員變量分配內存,類成員變量自然這個時候也不能被初始化)。==但是這裏的初始化指的是為變量賦予 Java 語言中該數據類型的默認值,而不是用戶代碼里初始化的值。==
例如下面的代碼在準備階段之後,LeiBianLiang 的值將是 0,而不是 666。
public static int LeiBianLiang = 666;
注意了!!!
注意了!!!
注意了!!!
但如果一個變量是常量(被 static final 修飾)的話,那麼在準備階段,屬性便會被賦予用戶希望的值。例如下面的代碼在準備階段之後,ChangLiang的值將是 666,而不再會是 0。
public static final int ChangLiang = 666;
之所以 static final 會直接被複制,而 static 變量會被賦予java語言類型的默認值。其實我們稍微思考一下就能想明白了。
兩個語句的區別是一個有 final 關鍵字修飾,另外一個沒有。而 final 關鍵字在 Java 中代表不可改變的意思,意思就是說 ChangLiang的值一旦賦值就不會在改變了。既然一旦賦值就不會再改變,那麼就必須一開始就給其賦予用戶想要的值,因此被 final 修飾的類變量在準備階段就會被賦予想要的值。而沒有被 final 修飾的類變量,其可能在初始化階段或者運行階段發生變化,所以就沒有必要在準備階段對它賦予用戶想要的值。
如果還不是很清晰理解final和static關鍵字的話建議參閱下面博主整理好的文章,希望對你有所幫助!
2、4.解析
當通過準備階段之後,進入解析階段。解析階段是虛擬機將常量池內的符號引用替換為直接引用的過程,解析動作主要針對類或接口、字段、類方法、接口方法、方法類型、方法句柄和調用點限定符7類符號引用進行。符號引用就是一組符號來描述目標,可以是任何字面量。
直接引用就是直接指向目標的指針、相對偏移量或一個間接定位到目標的句柄。
==其實這個階段對於我們來說也是幾乎透明的,了解一下就好==。
2、5.初始化【重點】
到了初始化階段,用戶定義的 Java 程序代碼才真正開始執行。
Java程序對類的使用方式可分為兩種:主動使用與被動使用。一般來說只有當對類的==首次主動使用==的時候才會導致類的初始化,所以主動使用又叫做類加載過程中“初始化”開始的時機。那啥是主動使用呢?類的主動使用包括以下六種【超級重點】:
1、 創建類的實例,也就是new的方式
2、 訪問某個類或接口的靜態變量,或者對該靜態變量賦值(凡是被final修飾不不不其實更準確的說是在編譯器把結果放入常量池的靜態字段除外)
3、 調用類的靜態方法
4、 反射(如 Class.forName(“com.gx.yichun”))
5、 初始化某個類的子類,則其父類也會被初始化
6、 Java虛擬機啟動時被標明為啟動類的類( JavaTest ),還有就是Main方法的類會
首先被初始化
最後注意一點對於靜態字段,只有直接定義這個字段的類才會被初始化(執行靜態代碼塊),這句話在繼承、多態中最為明顯!為了方便理解下文會陸續通過例子講解
2、6.使用
當 JVM 完成初始化階段之後,JVM 便開始從入口方法開始執行用戶的程序代碼。這個使用階段也只是了解一下就可以了。
2、7.卸載
當用戶程序代碼執行完畢后,JVM 便開始銷毀創建的 Class 對象,最後負責運行的 JVM 也退出內存。這個卸載階段也只是了解一下就可以了。
2、8.結束生命周期
在如下幾種情況下,Java虛擬機將結束生命周期
1、 執行了 System.exit()方法
2、 程序正常執行結束
3、 程序在執行過程中遇到了異常或錯誤而異常終止
4、 由於操作系統出現錯誤而導致Java虛擬機進程終止
3、接口的加載過程
接口加載過程與類加載過程稍有不同。
==當一個類在初始化時,要求其父類全部都已經初始化過了,但是一個接口在初始化時,並不要求其父接口全部都完成了初始化,當真正用到父接口的時候才會初始化。==
4、解開開篇的面試題
package com.jvm.classloader;
class Father2{
public static String strFather="HelloJVM_Father";
static{
System.out.println("Father靜態代碼塊");
}
}
class Son2 extends Father2{
public static String strSon="HelloJVM_Son";
static{
System.out.println("Son靜態代碼塊");
}
}
public class InitativeUseTest2 {
public static void main(String[] args) {
System.out.println(Son2.strSon);
}
}
運行結果:
Father靜態代碼塊
Son靜態代碼塊
HelloJVM_Son
再回頭看這個題,這也太簡單了吧,由於Son2.strSon是調用了Son類自己的靜態方法屬於主動使用,所以會初始化Son類,又由於繼承關係,類繼承原則是初始化一個子類,會先去初始化其父類,所以會先去初始化父類!
再看開篇的第二個題
package com.jvm.classloader;
class YeYe{
static {
System.out.println("YeYe靜態代碼塊");
}
}
class Father extends YeYe{
public static String strFather="HelloJVM_Father";
static{
System.out.println("Father靜態代碼塊");
}
}
class Son extends Father{
public static String strSon="HelloJVM_Son";
static{
System.out.println("Son靜態代碼塊");
}
}
public class InitiativeUse {
public static void main(String[] args) {
System.out.println(Son.strFather);
}
}
運行結果:
YeYe靜態代碼塊
Father靜態代碼塊
HelloJVM_Father
這個題就稍微要注意一下,不過要是你看懂這篇文章,這個題也很簡單。這個題要注意什麼呢?要注意子類Son類沒有被初始化,也就是Son的靜態代碼塊沒有執行!發現了咩?那我們來分析分析…
首先看到Son.strFather,你會發現是子類Son訪問父類Father的靜態變量strFather,這個時候就千萬要記住我在歸納主動使用概念時特別提到過的一個注意點了:對於靜態字段,只有直接定義這個字段的類才會被初始化(執行靜態代碼塊),這句話在繼承、多態中最為明顯!
嗯哼,對吧,Son.strFather中的靜態字段是屬於父類Father的對吧,也就是說直接定義這個字段的類是父類Father,所以在執行 System.out.println(Son.strFather); 這句代碼的時候會去初始化Father類而不是子類Son!是不是一下子明白了?如果明白了就支持一下博主點個讚唄,謝謝~
再看開篇的第三個題
package com.jvm.classloader;
class YeYe{
static {
System.out.println("YeYe靜態代碼塊");
}
}
class Father extends YeYe{
public final static String strFather="HelloJVM_Father";
static{
System.out.println("Father靜態代碼塊");
}
}
class Son extends Father{
public static String strSon="HelloJVM_Son";
static{
System.out.println("Son靜態代碼塊");
}
}
public class InitiativeUse {
public static void main(String[] args) {
System.out.println(Son.strFather);
}
}
運行結果:HelloJVM_Father
這個題唯一的特點就在於final static !是的Son.strFather所對應的變量便是final static修飾的,依舊是在本篇文章中歸納的類的主動使用範疇第二點當中:訪問某個類或接口的靜態變量,或者對該靜態變量賦值(凡是被final修飾不不不其實更準確的說是在編譯器把結果放入常量池的靜態字段除外)
所以,這個題並不會初始化任何類,當然除了Main方法所在的類!於是僅僅執行了System.out.println(Son.strFather);所以僅僅打印了Son.strFather的字段結果HelloJVM_Father,嗯哼,是不是又突然明白了?如果明白了就再支持一下博主點個讚唄,謝謝~
實際上上面的題目並不能完全說明本篇文章中歸納的類的主動使用範疇第二點!這話怎麼說呢?怎麼理解呢?再來一個程序各位就更加明了了
package com.jvm.classloader;
import sun.applet.Main;
import java.util.Random;
import java.util.UUID;
class Test{
static {
System.out.println("static 靜態代碼塊");
}
// public static final String str= UUID.randomUUID().toString();
public static final double str=Math.random(); //編譯期不確定
}
public class FinalUUidTest {
public static void main(String[] args) {
System.out.println(Test.str);
}
}
請試想一下結果,會不會執行靜態代碼塊里的內容呢?
重點來了
重點來了
重點來了
重點來了
運行結果
static 靜態代碼塊
0.7338688977344875
上面這個程序完全說明本篇文章中歸納的類的主動使用範疇第二點當中的這句話:凡是被final修飾不不不其實更準確的說是在編譯器把結果放入常量池的靜態字段除外!
分析:==其實final不是重點,重點是編譯器把結果放入常量池!當一個常量的值並非編譯期可以確定的,那麼這個值就不會被放到調用類的常量池中,這時在程序運行時,會導致主動使用這個常量所在的類,所以這個類會被初始化==
到這裏,能理解完上面三個題已經很不錯了,但是要想更加好好的學習java,博主不得不給各位再來一頓燒腦盛宴,野心不大,只是單純的想巔覆各位對java代碼的認知,當然還望大佬輕拍哈哈哈,直接上代碼:
package com.jvm.classloader;
public class ClassAndObjectLnitialize {
public static void main(String[] args) {
System.out.println("輸出的打印語句");
}
public ClassAndObjectLnitialize(){
System.out.println("構造方法");
System.out.println("我是熊孩子我的智商=" + ZhiShang +",情商=" + QingShang);
}
{
System.out.println("普通代碼塊");
}
int ZhiShang = 250;
static int QingShang = 666;
static
{
System.out.println("靜態代碼塊");
}
}
建議這個題不要花太多時間思考,否則看了結果你會發現自己想太多了,導致最後可能你看到結果想砸電腦哈哈哈
隔離運行結果專業跑龍套…
隔離運行結果專業跑龍套…
隔離運行結果專業跑龍套…
隔離運行結果專業跑龍套…
隔離運行結果專業跑龍套…
運行結果
靜態代碼塊
輸出的打印語句
怎麼樣,是不是沒有你想的那麼複雜呢?
下面我們來簡單分析一下,首先根據上面說到的觸發初始化的(主動使用)的第六點:Java虛擬機啟動時被標明為啟動類的類( JavaTest ),還有就是Main方法的類會首先被初始化
嗯哼?小白童鞋就有疑問了:不是說好有Main方法的類會被初始化的么?那怎麼好多東西都沒有執行捏?
那麼類的初始化順序到底是怎麼樣的呢?在我們代碼中,我們只知道有一個構造方法,但實際上Java代碼編譯成字節碼之後,最開始是沒有構造方法的概念的,只有==類初始化方法== 和 ==對象初始化方法== 。
這個時候我們就不得不深入理解了!那麼這兩個方法是怎麼來的呢?
類初始化方法:編譯器會按照其出現順序,收集:類變量(static變量)的賦值語句、靜態代碼塊,最終組成類初始化方法。==類初始化方法一般在類初始化的時候執行。==
所以,上面的這個例子,類初始化方法就會執行下面這段代碼了:
static int QingShang = 666; //類變量(static變量)的賦值語句
static //靜態代碼塊
{
System.out.println("靜態代碼塊");
}
而不會執行普通賦值語句以及普通代碼塊了
對象初始化方法:編譯器會按照其出現順序,收集:成員變量的賦值語句、普通代碼塊,最後收集構造函數的代碼,最終組成對象初始化方法,值得特別注意的是,如果沒有監測或者收集到構造函數的代碼,則將不會執行對象初始化方法。==對象初始化方法一般在實例化類對象的時候執行。==
以上面這個例子,其對象初始化方法就是下面這段代碼了:
{
System.out.println("普通代碼塊"); //普通代碼塊
}
int ZhiShang = 250; //成員變量的賦值語句
System.out.println("構造方法"); //最後收集構造函數的代碼
System.out.println("我是熊孩子我的智商=" + ZhiShang +",情商=" + QingShang);
明白了類初始化方法 和 對象初始化方法 之後,我們再來看這個上面例子!是的!正如上面提到的:如果沒有監測或者收集到構造函數的代碼,則將不會執行對象初始化方法。上面的這個例子確實沒有執行對象初始化方法。忘了嗎?我們根本就沒有對類ClassAndObjectLnitialize 進行實例化!只是單純的寫了一個輸出語句。
如果我們給其實例化,驗證一下,代碼如下:
package com.jvm.classloader;
public class ClassAndObjectLnitialize {
public static void main(String[] args) {
new ClassAndObjectLnitialize();
System.out.println("輸出的打印語句");
}
public ClassAndObjectLnitialize(){
System.out.println("構造方法");
System.out.println("我是熊孩子我的智商=" + ZhiShang +",情商=" + QingShang);
}
{
System.out.println("普通代碼塊");
}
int ZhiShang = 250;
static int QingShang = 666;
static
{
System.out.println("靜態代碼塊");
}
}
運行結果:
靜態代碼塊
普通代碼塊
構造方法
我是熊孩子我的智商=250,情商=666
輸出的打印語句
到這裏博主必須要聲明一點了!我為什麼要用這些面試題作為這篇文章的一部分?因為關於學習有一定的方法,你可以設想一下,如果博主不涉及並分析這幾個面試題,你還有耐心看到這裏嗎?小白杠精童鞋說有。。。好的,就算有,大篇大篇的理論各位扣心自問,能掌握所有知識嗎?小白杠精童鞋說說能。。。額,就算能,那你能保證光記理論一個月不遺忘嗎?小白杠精童鞋說可以。。。我特么一老北京布鞋過去頭給你打歪(我這暴脾氣我天)。所以呢學習要帶着興趣、“目的”、“野心”!希望我這段話能對你有所幫助,哪怕是一點點…
5、理解首次主動使用
我在上面提到過Java程序對類的使用方式可分為兩種:主動使用與被動使用。一般來說只有當對類的首次主動使用的時候才會導致類的初始化,其中首次關鍵字很重要,因此特地用一小結將其講解!
怎麼理解呢?老規矩看個題:
package com.jvm.classloader;
class Father6{
public static int a = 1;
static {
System.out.println("父類粑粑靜態代碼塊");
}
}
class Son6{
public static int b = 2;
static {
System.out.println("子類熊孩子靜態代碼塊");
}
}
public class OverallTest {
static {
System.out.println("Main方法靜態代碼塊");
}
public static void main(String[] args) {
Father6 father6;
System.out.println("======");
father6=new Father6();
System.out.println("======");
System.out.println(Father6.a);
System.out.println("======");
System.out.println(Son6.b);
}
}
請試想一下運行結果
運行結果:
Main方法靜態代碼塊
======
父類粑粑靜態代碼塊
======
1
======
子類熊孩子靜態代碼塊
2
分析:
首先根據主動使用概括的第六點:Main方法的類會首先被初始化。 所以最先執行Main方法靜態代碼塊,而 Father6 father6;只是聲明了一個引用不會執行什麼,當運行到father6=new Father6();的時候,看到關鍵字new並且將引用father6指向了Father6對象,說明主動使用了,所以父類Father6將被初始化,因此打印了:父類粑粑靜態代碼塊 ,之後執行 System.out.println(Father6.a);屬於訪問靜態變量所以也是主動使用,這個時候注意了,因為在上面執行father6=new Father6();的時候父類已經主動使用並且初始化過一次了,這次不再是首次主動使用了,所以Father6不會在被初始化,自然它的靜態代碼塊就不再執行了,所以直接打印靜態變量值1,而後面的System.out.println(Son6.b);同樣,也是只初始化自己,不會去初始化父類,只因為父類Father6以及不再是首次主動使用了!明白了沒?如果有疑問歡迎留言,絕對第一時間回復!
6、類加載器
喔o,終於到類加載器內容了!我們之前講的類加載都是給類加載器做的一個伏筆,在這之前講的所有類被加載都是由類加載器來完成的,可見類加載器是多麼重要。由於上面的面試題並不涉及類加載器的相關知識,所以到這裏再涉及涉及類加載器的知識!
類加載器負責加載所有的類,其為所有被載入內存中的類生成一個java.lang.Class實例對象。一旦一個類被加載入JVM中,同一個類就不會被再次載入了。正如一個對象有一個唯一的標識一樣,一個載入JVM的類也有一個唯一的標識。
關於唯一標識符:
在Java中,一個類用其全限定類名(包括包名和類名)作為標識;
但在JVM中,一個類用其全限定類名和其類加載器作為其唯一標識。
類加載器的任務是根據一個類的全限定名來讀取此類的二進制字節流到JVM中,然後轉換為一個與目標類對應的java.lang.Class對象實例,在虛擬機提供了3種類加載器,啟動(Bootstrap)類加載器、擴展(Extension)類加載器、系統(System)類加載器(也稱應用類加載器),如下:
站在Java開發人員的角度來看,類加載器可以大致劃分為以下三類:
啟動類加載器: BootstrapClassLoader,啟動類加載器主要加載的是JVM自身需要的類,這個類加載使用C++語言實現的,是虛擬機自身的一部分,負責加載存放在 JDK\jre\lib(JDK代表JDK的安裝目錄,下同)下,或被 -Xbootclasspath參數指定的路徑中的,並且能被虛擬機識別的類庫(如rt.jar,所有的java.開頭的類均被 BootstrapClassLoader加載)。啟動類加載器是無法被Java程序直接引用的。==總結一句話:啟動類加載器加載java運行過程中的核心類庫JRE\lib\rt.jar, sunrsasign.jar, charsets.jar, jce.jar, jsse.jar, plugin.jar 以及存放在JRE\classes里的類,也就是JDK提供的類等常見的比如:Object、Stirng、List…==
擴展類加載器: ExtensionClassLoader,該加載器由 sun.misc.Launcher$ExtClassLoader實現,它負責加載 JDK\jre\lib\ext目錄中,或者由 java.ext.dirs系統變量指定的路徑中的所有類庫(如javax.開頭的類),開發者可以直接使用擴展類加載器。
應用程序類加載器: ApplicationClassLoader,該類加載器由 sun.misc.Launcher$AppClassLoader來實現,它負責加載用戶類路徑(ClassPath)所指定的類,開發者可以直接使用該類加載器,如果應用程序中沒有自定義過自己的類加載器,一般情況下這個就是程序中默認的類加載器。==總結一句話:應用程序類加載器加載CLASSPATH變量指定路徑下的類 即指你自已在項目工程中編寫的類==
線程上下文類加載器:除了以上列舉的三種類加載器,還有一種比較特殊的類型就是線程上下文類加載器。類似Thread.currentThread().getContextClassLoader()獲取線程上下文類加載器
在Java的日常應用程序開發中,類的加載幾乎是由上述3種類加載器相互配合執行的,在必要時,我們還可以自定義類加載器,因為JVM自帶的類加載器(ClassLoader)只是懂得從本地文件系統加載標準的java class文件,因此如果編寫了自己的ClassLoader,便可以做到如下幾點:
1、在執行非置信代碼之前,自動驗證数字簽名。
2、動態地創建符合用戶特定需要的定製化構建類。
3、從特定的場所取得java class,例如數據庫中和網絡中。
需要注意的是,Java虛擬機對class文件採用的是按需加載的方式,也就是說當需要使用該類時才會將它的class文件加載到內存生成class對象,而且加載某個類的class文件時,Java虛擬機默認採用的是雙親委派模式即把請求交由父類處理,它一種任務委派模式,下面將會詳細講到!
下面我們看一個程序:
package com.jvm.classloaderQi;
public class ClassloaderTest {
public static void main(String[] args) {
//獲取ClassloaderTest類的加載器
ClassLoader classLoader= ClassloaderTest.class.getClassLoader();
System.out.println(classLoader);
System.out.println(classLoader.getParent()); //獲取ClassloaderTest類的父類加載器
System.out.println(classLoader.getParent().getParent());
}
}
運行結果:
sun.misc.Launcher$AppClassLoader@18b4aac2
sun.misc.Launcher$ExtClassLoader@1b6d3586
null
從上面的結果可以看出,並沒有獲取到ExtClassLoader的父Loader,原因是Bootstrap Loader(啟動類加載器)是用C++語言實現的(這裏僅限於Hotspot,也就是JDK1.5之後默認的虛擬機,有很多其他的虛擬機是用Java語言實現的),找不到一個確定的返回父Loader的方式,於是就返回null。至於$符號就是內部類的含義。
7、關於命名空間
我覺得講類加載器,還是很有必要知道命名空間這個概念!實際上類加載器的一個必不可少的前提就是命名空間!
命名空間概念:
每個類加載器都有自己的命名空間,命名空間由該加載器及所有父加載器所加載的類組成。
特別注意:
在同一個命名空間中,不會出現類的完整名字(包括類的包名)相同的兩個類。
在不同的命名空間中,有可能會出現類的完整名字(包括類的包名)相同的兩個類。
由子加載器加載的類能看見父加載器的類,由父親加載器加載的類不能看見子加載器加載的類
我們已經知道每個類只能被加載一次,其實這樣說是不夠準確的,怎樣才算是準確的呢?那就涉及到命名空間的概念了!只有在相同的命名空間中,每個類才只能被加載一次,反過來說就是一個類在不同的命名空間中是可以被加載多次的,而被加載多次的Class對象是互相獨立的!
7.1、如何理解?
當然,直接把命名空間的概念直接拋給大家,如果沒有接觸過,100%是看不懂其中的含義的,我敢打包票,假一賠100萬。。。那麼博主就舉出寫例子讓各位深刻體會一下!當然這些例子涉及自定義加載器的一些知識,建議先對自定義加載器有一定了解在看!
例子必知前提:
1、 自己在idea或者eclipse中創建的工程項目中只要編譯之後都會有對應的class文件成在classPath目錄中
2、 而這些目錄是由ApplicationClassLoader應用加載器加載
3、 我之後會將class文件放到系統桌面地址上,而這些系統地址由自定義加載器指定,所以由自定義加載器加載
7.2、準備
事先編譯好,然後將項目工程中的兩個字節碼class文件【File1和File2】拷貝到系統桌面路徑上,編譯main方法就會出現在項目工程(ClassPath)下,注意以下例子情況中系統桌面路徑的class文件一直都存在!
Main方法情況:
File1類的方法情況:
- 1、
File1的構造方法中存在一行代碼:new File2 的new實例代碼
File2類的方法情況:
7.3、測試代碼情景一
刪除File1、File2項目工程中的class文件,工程項目的兩個class文件都刪除(只存在系統桌面路徑下的class文件)
結果:File1和File2的加載器都是自定義加載器
7.4、測試代碼情景二
只刪除File1項目工程中的class文件
結果:File1的加載器是自定義加載器,而執行到File2實例的加載器是App應用加載器
7.5、測試代碼情景三
只刪除File2項目工程中的class文件
結果:File1的加載器都是APP應用加載器,而執行到File2實例的時候報NoClassDefFoundError異常
得出結論:加載一個類(File1)的時候,這個類裏面調用了其他的類(File2)或者其他類方法的初始化代碼,那麼這裏面的類也會試着從這個類的加載器開始向上委託加載,如果全都加載不了加載不了就報NoClassDefFoundError異常。
當然這樣理解命名空間和類加載機制還是遠遠不夠的!
File2類中發生改變情況如下:
- 1、
File1的構造方法中存在一行new File2的實例這沒變
- 2、在
File2的構造方法中,打印(訪問)File1的class文件
7.6、測試代碼情景四
只刪除項目工程中File1的class文件
結果:File1的加載器都是自定義加載器,而執行到File2實例的加載器是App應用加載器,當運行到File2構造方法中的打印(訪問)File1的class文件的時候報NoClassDefFoundError異常
得出結論:父親加載器加載的類(File2)不能看見子加載器加載的類(File1)
File1方法發生改變情況如下:
1、Main方法中newInstance出File1的實例,File1的構造方法中存在一行new File2的實例這都沒變
2、在File1的構造方法中,打印File2的class文件
7.7、測試代碼情景五
只刪除File1項目工程中的class文件
結果:File1的加載器都是自定義加載器,而執行到File2實例的加載器是App應用加載器,當運行到File1構造方法中的打印File2的class文件的時候沒問題
得出結論:由子加載器加載的類(File1)能看見父加載器的類(File2)
當然還要注意知道的一點的是:如果兩個加載器之間沒有直接或間接的父子關係,那麼它們各自加載類相互不可見。
當然整對上面的情況還是相當比較抽象,畢竟沒上代碼,如果有任何疑問,歡迎留言,宜春絕對第一時間回復!
8、JVM類加載機制
JVM的類加載機制主要有如下3種。
全盤負責:當一個類加載器負責加載某個Class時,該Class所依賴的和引用的其他Class也將由該類加載器負責載入,除非显示使用另外一個類加載器來載入
父類委託:先讓父類加載器試圖加載該類,只有在父類加載器無法加載該類時才嘗試從自己的類路徑中加載該類,通俗講就是兒子們都他么是懶豬,自己不管能不能做,就算能加載也先不幹,先給自己的父親做,一個一個往上拋,直到拋到啟動類加載器也就是最頂級父類,只有父親做不了的時候再沒辦法由下一個子類做,直到能某一個子類能做才做,之後的子類就直接返回,實力坑爹!
緩存機制:緩存機制將會保證所有加載過的Class都會被緩存,當程序中需要使用某個Class時,類加載器先從緩存區尋找該Class,只有緩存區不存在,系統才會讀取該類對應的二進制數據,並將其轉換成Class對象,存入緩存區。這就是為什麼修改了Class后,必須重啟JVM,程序的修改才會生效
9、雙親委派模型
雙親委派模型的工作流程是:如果一個類加載器收到了類加載的請求,它首先不會自己去嘗試加載這個類,而是把請求委託給父加載器去完成,依次向上,因此,所有的類加載請求最終都應該被傳遞到頂層的啟動類加載器中,只有當父加載器在它的搜索範圍中沒有找到所需的類時,即無法完成該加載,子加載器才會嘗試自己去加載該類。也就是實力坑爹!
雙親委派機制:
1、當AppClassLoader加載一個class時,它首先不會自己去嘗試加載這個類,而是把類加載請求委派給父類加載器ExtClassLoader去完成。
2、當 ExtClassLoader加載一個class時,它首先也不會自己去嘗試加載這個類,而是把類加載請求委派給BootStrapClassLoader去完成。
3、如果 BootStrapClassLoader加載失敗(例如在 $JAVA_HOME/jre/lib里未查找到該class),會使用
ExtClassLoader來嘗試加載;
4、若ExtClassLoader也加載失敗,則會使用 AppClassLoader來加載,如果
AppClassLoader也加載失敗,則會報出異常 ClassNotFoundException。
從代碼層面了解幾個Java中定義的類加載器及其雙親委派模式的實現,它們類圖關係如下:
從圖可以看出頂層的類加載器是
抽象類ClassLoader類,其後
所有的類加載器都繼承自ClassLoader(不包括啟動類加載器),為了更好理解雙親委派模型,ClassLoader源碼中的loadClass(String)方法該方法加載指定名稱(包括包名)的二進制類型,該方法在JDK1.2之後不再建議用戶重寫但用戶可以直接調用該方法,
loadClass()方法是ClassLoader類自己實現的,該方法中的邏輯就是雙親委派模式的實現,loadClass(String name, boolean resolve)是一個重載方法,resolve參數代表是否生成class對象的同時進行解析相關操作。源碼分析如下::
public Class<?> loadClass(String name) throws ClassNotFoundException {
return loadClass(name, false);
}
protected Class<?> loadClass(String name, boolean resolve)
throws ClassNotFoundException
{
synchronized (getClassLoadingLock(name)) {
// 先從緩存查找該class對象,找到就不用重新加載
Class<?> c = findLoadedClass(name);
if (c == null) {
long t0 = System.nanoTime();
try {
if (parent != null) {
//如果找不到,則委託給父類加載器去加載
c = parent.loadClass(name, false);
} else {
//如果沒有父類,則委託給啟動加載器去加載
c = findBootstrapClassOrNull(name);
}
} catch (ClassNotFoundException e) {
// ClassNotFoundException thrown if class not found
// from the non-null parent class loader
}
if (c == null) {
// If still not found, then invoke findClass in order
// 如果都沒有找到,則通過自定義實現的findClass去查找並加載
c = findClass(name);
// this is the defining class loader; record the stats
sun.misc.PerfCounter.getParentDelegationTime().addTime(t1 - t0);
sun.misc.PerfCounter.getFindClassTime().addElapsedTimeFrom(t1);
sun.misc.PerfCounter.getFindClasses().increment();
}
}
if (resolve) {//是否需要在加載時進行解析
resolveClass(c);
}
return c;
}
}
既然存在這個雙親委派模型,那麼就一定有着存在的意義,其意義主要是:Java類隨着它的類加載器一起具備了一種帶有優先級的層次關係,通過這種層級關可以避免類的重複加載,當父親已經加載了該類時,就沒有必要子ClassLoader再加載一次。其次是考慮到安全因素,java核心api中定義類型不會被隨意替換,假設通過網絡傳遞一個名為java.lang.Integer的類,通過雙親委託模式傳遞到啟動類加載器,而啟動類加載器在核心Java API發現這個名字的類,發現該類已被加載,並不會重新加載網絡傳遞的過來的java.lang.Integer,而直接返回已加載過的Integer.class,這樣便可以防止核心API庫被隨意篡改。
雙親委派模型意義總結來講就是:
1、系統類防止內存中出現多份同樣的字節碼
2、保證Java程序安全穩定運行
10、ClassLoader源碼分析
ClassLoader類是一個抽象類,所有的類加載器都繼承自ClassLoader(不包括啟動類加載器),因此它顯得格外重要,分析ClassLoader抽象類也是非常重要的!
簡單小結一下ClassLoader抽象類中一些概念:
二進制概念(Binary name):格式如下
把二進制名字轉換成文件名字,然後在文件系統中磁盤上讀取其二進制文件(class文件),每一個class對象都包含了定義了這個類的classload對象,class類都是由類加載器加載的只有數組類型是有JVM根據需要動態生成。
特別注意數組類型:
1、 數組類的類對象不是由類加載器創建的,而是根據Java運行時的需要自動創建的。
2、 數組類的類加載器getClassLoader()與它的元素類型的類加載器相同;如果元素類型是基本類型,則數組類沒有類加載器也就是null,而這個null不同於根類加載器返回的null,它是單純的null。
到這裏,下面就主要分析ClassLoader抽象類中幾個比較重要的方法。
10、1.loadClass
該方法加載指定名稱(包括包名)的二進制類型,該方法在JDK1.2之後不再建議用戶重寫但用戶可以直接調用該方法,loadClass()方法是ClassLoader類自己實現的,該方法中的邏輯就是雙親委派模式的實現,其源碼如下,loadClass(String name, boolean resolve)是一個重載方法,resolve參數代表是否生成class對象的同時進行解析相關操作:
public Class<?> loadClass(String name) throws ClassNotFoundException {
return loadClass(name, false);
}
protected Class<?> loadClass(String name, boolean resolve)
throws ClassNotFoundException
{
synchronized (getClassLoadingLock(name)) {
// 先從緩存查找該class對象,找到就不用重新加載
Class<?> c = findLoadedClass(name);
if (c == null) {
long t0 = System.nanoTime();
try {
if (parent != null) {
//如果找不到,則委託給父類加載器去加載
c = parent.loadClass(name, false);
} else {
//如果沒有父類,則委託給啟動加載器去加載
c = findBootstrapClassOrNull(name);
}
} catch (ClassNotFoundException e) {
// ClassNotFoundException thrown if class not found
// from the non-null parent class loader
}
if (c == null) {
// If still not found, then invoke findClass in order
// 如果都沒有找到,則通過自定義實現的findClass去查找並加載
c = findClass(name);
// this is the defining class loader; record the stats
sun.misc.PerfCounter.getParentDelegationTime().addTime(t1 - t0);
sun.misc.PerfCounter.getFindClassTime().addElapsedTimeFrom(t1);
sun.misc.PerfCounter.getFindClasses().increment();
}
}
if (resolve) {//是否需要在加載時進行解析
resolveClass(c);
}
return c;
}
}
正如loadClass方法所展示的,當類加載請求到來時,先從緩存中查找該類對象,如果存在直接返回,如果不存在則交給該類加載去的父加載器去加載,倘若沒有父加載則交給頂級啟動類加載器去加載,最後倘若仍沒有找到,則使用findClass()方法去加載(關於findClass()稍後會進一步介紹)。從loadClass實現也可以知道如果不想重新定義加載類的規則,也沒有複雜的邏輯,只想在運行時加載自己指定的類,那麼我們可以直接使用this.getClass().getClassLoder.loadClass(“className”),這樣就可以直接調用ClassLoader的loadClass方法獲取到class對象。
10、2.findClass
在JDK1.2之前,在自定義類加載時,總會去繼承ClassLoader類並重寫loadClass方法,從而實現自定義的類加載類,但是在JDK1.2之後已不再建議用戶去覆蓋loadClass()方法,而是建議把自定義的類加載邏輯寫在findClass()方法中,從前面的分析可知,findClass()方法是在loadClass()方法中被調用的,當loadClass()方法中父加載器加載失敗后,則會調用自己的findClass()方法來完成類加載,這樣就可以保證自定義的類加載器也符合雙親委託模式。需要注意的是ClassLoader類中並沒有實現findClass()方法的具體代碼邏輯,取而代之的是拋出ClassNotFoundException異常,同時應該知道的是findClass方法通常是和defineClass方法一起使用的(稍後會分析),ClassLoader類中findClass()方法源碼如下:
//直接拋出異常
protected Class<?> findClass(String name) throws ClassNotFoundException {
throw new ClassNotFoundException(name);
}
10、3.defineClass(byte[] b, int off, int len)
defineClass()方法是用來將byte字節流解析成JVM能夠識別的Class對象(ClassLoader中已實現該方法邏輯),通過這個方法不僅能夠通過class文件實例化class對象,也可以通過其他方式實例化class對象,如通過網絡接收一個類的字節碼,然後轉換為byte字節流創建對應的Class對象,defineClass()方法通常與findClass()方法一起使用,一般情況下,在自定義類加載器時,會直接覆蓋ClassLoader的findClass()方法並編寫加載規則,取得要加載類的字節碼後轉換成流,然後調用defineClass()方法生成類的Class對象,簡單例子如下:
protected Class<?> findClass(String name) throws ClassNotFoundException {
// 獲取類的字節數組
byte[] classData = getClassData(name);
if (classData == null) {
throw new ClassNotFoundException();
} else {
//使用defineClass生成class對象
return defineClass(name, classData, 0, classData.length);
}
}
需要注意的是,如果直接調用defineClass()方法生成類的Class對象,這個類的Class對象並沒有解析(也可以理解為鏈接階段,畢竟解析是鏈接的最後一步),其解析操作需要等待初始化階段進行。
10、4.resolveClass (Class<?>c)
使用該方法可以使用類的Class對象創建完成也同時被解析。前面我們說鏈接階段主要是對字節碼進行驗證,為類變量分配內存並設置初始值同時將字節碼文件中的符號引用轉換為直接引用。
10、5.ClassLoader小結
以上上述4個方法是ClassLoader類中的比較重要的方法,也是我們可能會經常用到的方法。接看SercureClassLoader擴展了 ClassLoader,新增了幾個與使用相關的代碼源(對代碼源的位置及其證書的驗證)和權限定義類驗證(主要指對class源碼的訪問權限)的方法,一般我們不會直接跟這個類打交道,更多是與它的子類URLClassLoader有所關聯,前面說過,ClassLoader是一個抽象類,很多方法是空的沒有實現,比如 findClass()、findResource()等。而URLClassLoader這個實現類為這些方法提供了具體的實現,並新增了URLClassPath類協助取得Class字節碼流等功能,在編寫自定義類加載器時,如果沒有太過於複雜的需求,可以直接繼承URLClassLoader類,這樣就可以避免自己去編寫findClass()方法及其獲取字節碼流的方式,使自定義類加載器編寫更加簡潔。
檢查完父類加載器之後loadClass會去默認調用findClass方法,父類(ClassLoader)中的findClass方法主要是拋出一個異常。
findClass根據二進制名字找到對應的class文件,返回值為Class對象Class<?>
defineClass這個方法主要是將一個字節數組轉換成Class實例,會拋三個異常,但只是threws一個,因為其他兩個是運行時異常。
loadClass方法是一個加載一個指定名字的class文件,調用findLoadedClass (String)檢查類是否已經加載…如果已經加裝就不再加載而是直接返回第一次加載結果 所以一個類只會加載一次
11、自定義類加載器
自定義核心目的是擴展java虛擬機的動態加載類的機制,JVM默認情況是使用雙親委託機制,雖然雙親委託機制很安全極高但是有些情況我們需要自己的一種方式加載,==比如應用是通過網絡來傳輸 Java類的字節碼,為保證安全性,這些字節碼經過了加密處理,這時系統類加載器就無法對其進行加載,這樣則需要自定義類加載器來實現==。因此自定義類加載器也是很有必要的。
自定義類加載器一般都是繼承自 ClassLoader類,從上面對 loadClass方法來分析來看,我們只需要重寫 findClass 方法即可。自定義加載器中點:重寫findClass,下面直接看自定義類加載器代碼的流程:
package com.yichun.classloader;
import java.io.*;
public class MyClassLoader extends ClassLoader {
private String root;
protected Class<?> findClass(String name) throws ClassNotFoundException {
byte[] classData = loadClassData(name);
if (classData == null) {
throw new ClassNotFoundException();
} else {
return defineClass(name, classData, 0, classData.length);
}
}
private byte[] loadClassData(String className) {
String fileName = root + File.separatorChar
+ className.replace('.', File.separatorChar) + ".class";
try {
InputStream ins = new FileInputStream(fileName);
ByteArrayOutputStream baos = new ByteArrayOutputStream();
int bufferSize = 1024;
byte[] buffer = new byte[bufferSize];
int length = 0;
while ((length = ins.read(buffer)) != -1) {
baos.write(buffer, 0, length);
}
return baos.toByteArray();
} catch (IOException e) {
e.printStackTrace();
}
return null;
}
public String getRoot() {
return root;
}
public void setRoot(String root) {
this.root = root;
}
public static void main(String[] args) {
MyClassLoader classLoader = new MyClassLoader();
classLoader.setRoot("D:\\dirtemp");
Class<?> testClass = null;
try {
testClass = classLoader.loadClass("com.yichun.classloader.Demo1");
Object object = testClass.newInstance();
System.out.println(object.getClass().getClassLoader());
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (InstantiationException e) {
e.printStackTrace();
} catch (IllegalAccessException e) {
e.printStackTrace();
}
}
}
自定義類加載器的核心在於對字節碼文件的獲取,如果是加密的字節碼則需要在該類中對文件進行解密。上面代碼程序只是簡單Demo,並未對class文件進行加密,因此省略了解密的過程。這裡有幾點需要注意:
1、這裏傳遞的文件名需要是類的全限定性名稱,即com.yichun.test.classloading.Test格式的,因為
defineClass 方法是按這種格式進行處理的。
2、最好不要重寫loadClass方法,因為這樣容易破壞雙親委託模式。
3、這類Test 類本身可以被 AppClassLoader類加載,因此我們不能把com/yichun/test/classloading/Test.class放在類路徑下。否則,由於雙親委託機制的存在,會直接導致該類由AppClassLoader加載,而不會通過我們自定義類加載器來加載。
12、加載類的三種方式
到這裏,相信大家已經對類的加載以及加載器有一定的了解了,那麼你知道嗎,其實加載類常見的有三種方式,如下:
1、靜態加載,也就是通過new關鍵字來創建實例對象。
2、動態加載,也就是通過Class.forName()方法動態加載(反射加載類型),然後調用類的newInstance()方法實例化對象。
3、動態加載,通過類加載器的loadClass()方法來加載類,然後調用類的newInstance()方法實例化對象
12、1.三種方式的區別:
1、第一種和第二種方式使用的類加載器是相同的,都是當前類加載器。(this.getClass.getClassLoader)。而3由用戶指定類加載器。
2、如果需要在當前類路徑以外尋找類,則只能採用第3種方式。第3種方式加載的類與當前類分屬不同的命名空間。
3、第一種是靜態加載,而第二、三種是動態加載。
12、2.兩種異常(exception)
1、靜態加載的時候如果在運行環境中找不到要初始化的類,拋出的是NoClassDefFoundError,它在JAVA的異常體系中是一個Error
2、動態態加載的時候如果在運行環境中找不到要初始化的類,拋出的是ClassNotFoundException,它在JAVA的異常體系中是一個checked異常
12、3.理解Class.forName
Class.forName()是一種獲取Class對象的方法,而且是靜態方法。
Class.forName()是一個靜態方法,同樣可以用來加載類,Class.forName()返回與給定的字符串名稱相關聯類或接口的Class對象。注意這是一種獲取Class對象的方法
官方給出的API文檔如下
publicstatic Class<?> forName(String className)
Returns the Class object associated withthe class or interface with the given string name. Invokingthis method is equivalent to:
Class.forName(className,true, currentLoader)
where currentLoader denotes the definingclass loader of the current class.
For example, thefollowing code fragment returns the runtime Class descriptor for theclass named java.lang.Thread:
Class t =Class.forName("java.lang.Thread")
A call to forName("X") causes theclass named X to beinitialized.
Parameters:
className - the fully qualifiedname of the desired class.
Returns:
the Class object for the classwith the specified name.
可以看出,Class.forName(className)實際上是調用Class.forName(className,true, this.getClass().getClassLoader())。第二個參數,是指Class被loading后是不是必須被初始化。可以看出,使用Class.forName(className)加載類時則已初始化。所以Class.forName()方法可以簡單的理解為:獲得字符串參數中指定的類,並初始化該類。
12、4.Class.forName與ClassLoader.loadClass區別
首先,我們必須先明確類加載機制的三個過程主要是:加載 –> 連接 –> 初始化。
-
Class.forName():將類的.class文件加載到jvm中之外,還會對類進行解釋,執行類中的static塊;
-
ClassLoader.loadClass():只干一件事情,就是將.class文件加載到jvm中,不會執行static中的內容,只有在newInstance才會去執行static塊。
-
Class.forName(name, initialize, loader):帶參函數也可控制是否加載static塊。並且只有調用了newInstance()方法採用調用構造函數,創建類的對象 。
這個時候,我們再來看一個程序:
package com.jvm.classloader;
class Demo{
static {
System.out.println("static 靜態代碼塊");
}
}
public class ClassLoaderDemo {
public static void main(String[] args) throws ClassNotFoundException {
ClassLoader classLoader=ClassLoaderDemo.class.getClassLoader();
//1、使用ClassLoader.loadClass()來加載類,不會執行初始化塊
classLoader.loadClass("com.jvm.classloader.Demo");
//2、使用Class.forName()來加載類,默認會執行初始化塊
Class.forName("com.jvm.classloader.Demo");
//3、使用Class.forName()來加載類,並指定ClassLoader,初始化時不執行靜態塊
Class.forName("com.jvm.classloader.Demo",false,classLoader);
}
}
記得一個一個測試!我上面的程序是一次寫了三個的並且已經標明了標號1、2、3!!!各位再自個電腦上跑一遍,思路就很會清晰了!
13、總結
類的加載、連接與初始化:
1、加載:查找並加載類的二進制數據到java虛擬機中
2、 連接:
驗證: 確保被加載的類的正確性
準備:為類的靜態變量分配內存,並將其初始化為默認值,但是到達初始化之前類變量都沒有初始化為真正的初始值(如果是被 final 修飾的類變量,則直接會被初始成用戶想要的值。)
解析:把類中的符號引用轉換為直接引用,就是在類型的常量池中尋找類、接口、字段和方法的符號引用,把這些符號引用替換成直接引用的過程
3、 初始化:為類的靜態變量賦予正確的初始值
類從磁盤上加載到內存中要經歷五個階段:加載、連接、初始化、使用、卸載
Java程序對類的使用方式可分為兩種
(1)主動使用
(2)被動使用
所有的Java虛擬機實現必須在每個類或接口被Java程序“首次主動使用”時才能初始化他們
主動使用
(1)創建類的實例
(2)訪問某個類或接口的靜態變量 getstatic(助記符),或者對該靜態變量賦值 putstatic
(3)調用類的靜態方法 invokestatic
(4)反射(Class.forName(“com.test.Test”))
(5)初始化一個類的子類
(6)Java虛擬機啟動時被標明啟動類的類以及包含Main方法的類
(7)JDK1.7開始提供的動態語言支持(了解)
被動使用
除了上面七種情況外,其他使用java類的方式都被看做是對類的被動使用,都不會導致類的初始化
14、特別注意
初始化入口方法。當進入類加載的初始化階段后,JVM 會尋找整個 main 方法入口,從而初始化 main 方法所在的整個類。當需要對一個類進行初始化時,會首先初始化類構造器(),之後初始化對象構造器()。
初始化類構造器:JVM 會按順序收集類變量的賦值語句、靜態代碼塊,最終組成類構造器由 JVM 執行。
初始化對象構造器:JVM 會按照收集成員變量的賦值語句、普通代碼塊,最後收集構造方法,將它們組成對象構造器,最終由 JVM 執行。值得特別注意的是,如果沒有監測或者收集到構造函數的代碼,則將不會執行對象初始化方法。對象初始化方法一般在實例化類對象的時候執行。
如果在初始化 main 方法所在類的時候遇到了其他類的初始化,那麼就先加載對應的類,加載完成之後返回。如此反覆循環,最終返回 main 方法所在類。
如果本文對你有一點點幫助,那麼請點個讚唄,謝謝~
最後,若有不足或者不正之處,歡迎指正批評,感激不盡!如果有疑問歡迎留言,絕對第一時間回復!
歡迎各位關注我的公眾號,一起探討技術,嚮往技術,追求技術,說好了來了就是盆友喔…
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※為什麼 USB CONNECTOR 是電子產業重要的元件?
※網頁設計一頭霧水??該從何著手呢? 找到專業技術的網頁設計公司,幫您輕鬆架站!
※想要讓你的商品成為最夯、最多人討論的話題?網頁設計公司讓你強力曝光
※想知道最厲害的台北網頁設計公司推薦、台中網頁設計公司推薦專業設計師”嚨底家”!!


















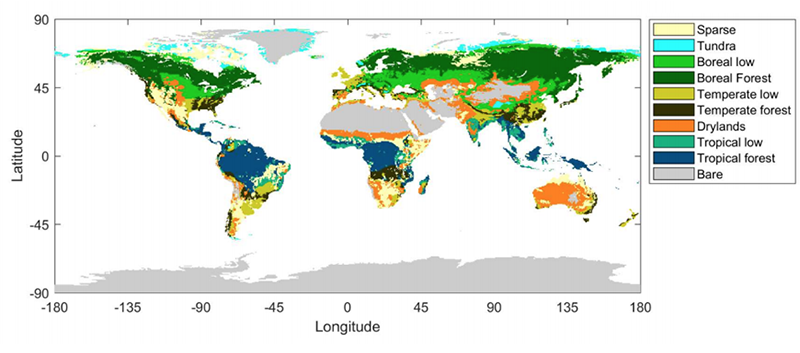 1992-2015年世界陸地生物群系分布,包括稀疏植生地(黃色)、苔原(藍色)、北寒低矮植生地(淺綠色)、北寒林(深綠色)、溫帶低矮植生地(橄欖)、溫帶森林(黑色)、旱地 (橙色)、熱帶低矮植生地(綠松石)、熱帶森林(深藍色)和裸露地(灰色)。 資料來源:Tagesson et al. (2020)
1992-2015年世界陸地生物群系分布,包括稀疏植生地(黃色)、苔原(藍色)、北寒低矮植生地(淺綠色)、北寒林(深綠色)、溫帶低矮植生地(橄欖)、溫帶森林(黑色)、旱地 (橙色)、熱帶低矮植生地(綠松石)、熱帶森林(深藍色)和裸露地(灰色)。 資料來源:Tagesson et al. (2020)  1992-2015年,北寒林(黑色)和熱帶森林(紅色)對陸域碳匯的貢獻。上色區域顯示不確定性範圍。資料來源:Tagesson et al. (2020)
1992-2015年,北寒林(黑色)和熱帶森林(紅色)對陸域碳匯的貢獻。上色區域顯示不確定性範圍。資料來源:Tagesson et al. (2020)